Note
Linking elements together#
As explained in the Data Structure chapter, momepy relies on links between different morphological elements. Each element needs ID, and each of the small-scale elements also needs to know the ID of the relevant higher-scale element. The case of block ID is explained in the previous chapter, momepy.Blocks generates it together with blocks gdf.
Getting the ID of the street network#
This notebook will explore how to link street network, both nodes and edges, to buildings and tessellation.
Edges#
For linking street network edges to buildings (or tessellation or other elements), momepy offers momepy.get_network_id. It simply returns a Series of network IDs for analysed gdf.
[1]:
import momepy
import geopandas as gpd
import matplotlib.pyplot as plt
For illustration, we can use bubenec dataset embedded in momepy.
[2]:
path = momepy.datasets.get_path('bubenec')
buildings = gpd.read_file(path, layer='buildings')
streets = gpd.read_file(path, layer='streets')
tessellation = gpd.read_file(path, layer='tessellation')
/Users/martin/Git/geopandas/geopandas/geodataframe.py:580: RuntimeWarning: Sequential read of iterator was interrupted. Resetting iterator. This can negatively impact the performance.
for feature in features_lst:
First, we have to be sure that streets segments have their unique IDs.
[3]:
streets['nID'] = momepy.unique_id(streets)
Then we can link it to buildings. The only argument we might want to look at is min_size, which should be a value such that if you build a box centred in each building centroid with edges of size 2 * min_size, you know a priori that at least one segment is intersected with the box. You can see it as a sort of tolerance.
[4]:
buildings['nID'] = momepy.get_network_id(buildings, streets,
'nID', min_size=100)
[5]:
f, ax = plt.subplots(figsize=(10, 10))
buildings.plot(ax=ax, column='nID', categorical=True, cmap='tab20b')
streets.plot(ax=ax)
ax.set_axis_off()
plt.show()

Note: colormap does not have enough colours, that is why everything on the top-left looks the same. It is not.
Nodes#
The situation with nodes is slightly more complicated as you usually don’t have or even need nodes. However, momepy includes some functions which are calculated on nodes (mostly in graph module). For that reason, we will pretend that we follow the usual workflow:
Street network
GeoDataFrame(edges only)networkx
GraphStreet network - edges and nodes as separate
GeoDataFrames.
[6]:
graph = momepy.gdf_to_nx(streets)
Some graph-based analysis happens here.
[7]:
nodes, edges = momepy.nx_to_gdf(graph)
[8]:
f, ax = plt.subplots(figsize=(10, 10))
edges.plot(ax=ax, column='nID', categorical=True, cmap='tab20b')
nodes.plot(ax=ax, zorder=2)
ax.set_axis_off()
plt.show()
For attaching node ID to buildings, we will need both, nodes and edges. We have already determined which edge building belongs to, so now we only have to find out which end of the edge is the closer one. Nodes come from momepy.nx_to_gdf automatically with node ID:
[9]:
nodes.head()
[9]:
| nodeID | geometry | |
|---|---|---|
| 0 | 0 | POINT (1603585.640 6464428.774) |
| 1 | 1 | POINT (1603413.206 6464228.730) |
| 2 | 2 | POINT (1603268.502 6464060.781) |
| 3 | 3 | POINT (1603363.558 6464031.885) |
| 4 | 4 | POINT (1603607.303 6464181.853) |
The same ID is now inlcuded in edges as well, denoting each end of edge. (Length of the edge is also present as it was necessary to keep as an attribute for the graph.)
[10]:
edges.head()
[10]:
| geometry | nID | mm_len | node_start | node_end | |
|---|---|---|---|---|---|
| 0 | LINESTRING (1603585.640 6464428.774, 1603413.2... | 0 | 264.103950 | 0 | 1 |
| 1 | LINESTRING (1603561.740 6464494.467, 1603564.6... | 14 | 70.020202 | 0 | 8 |
| 2 | LINESTRING (1603585.640 6464428.774, 1603603.0... | 15 | 88.924305 | 0 | 6 |
| 3 | LINESTRING (1603607.303 6464181.853, 1603592.8... | 2 | 199.746503 | 1 | 4 |
| 4 | LINESTRING (1603363.558 6464031.885, 1603376.5... | 5 | 203.014090 | 1 | 3 |
[11]:
buildings['nodeID'] = momepy.get_node_id(buildings, nodes, edges,
'nodeID', 'nID')
[12]:
f, ax = plt.subplots(figsize=(10, 10))
buildings.plot(ax=ax, column='nodeID', categorical=True, cmap='tab20b')
nodes.plot(ax=ax, zorder=2)
edges.plot(ax=ax, zorder=1)
ax.set_axis_off()
plt.show()
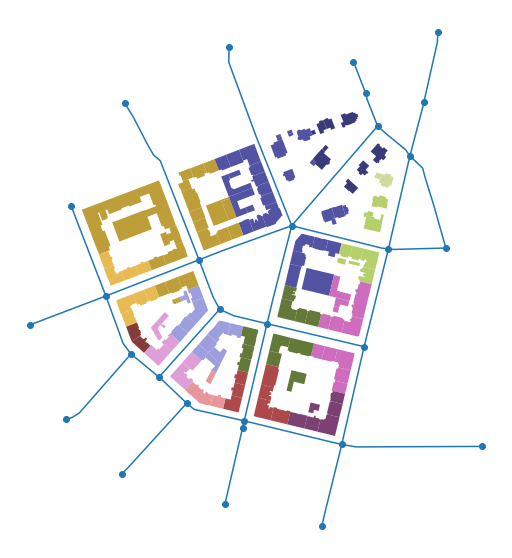
Transfer IDs to tessellation#
All IDs are now stored in buildings gdf. We can copy them to tessellation using merge. First, we select columns we are interested in, then we merge them with tessellation based on the shared unique ID. Usually, we will have more columns than we have now.
[13]:
buildings.columns
[13]:
Index(['uID', 'geometry', 'nID', 'nodeID'], dtype='object')
[14]:
columns = ['uID', 'nID', 'nodeID']
tessellation = tessellation.merge(buildings[columns], on='uID')
tessellation.head()
[14]:
| uID | geometry | nID | nodeID | |
|---|---|---|---|---|
| 0 | 1.0 | POLYGON ((1603578.489 6464344.527, 1603577.040... | 0 | 0 |
| 1 | 2.0 | POLYGON ((1603067.112 6464177.926, 1603054.848... | 33 | 9 |
| 2 | 3.0 | POLYGON ((1602978.618 6464156.859, 1603006.384... | 10 | 11 |
| 3 | 4.0 | POLYGON ((1603056.595 6464093.903, 1603011.539... | 10 | 11 |
| 4 | 5.0 | POLYGON ((1603110.459 6464114.367, 1603109.099... | 8 | 11 |
Now we should be able to link all elements together as needed for all types of morphometric analysis in momepy.